
Expoloitation 과 expoloration은 trade off관계임.
알고있는걸 계속 연구하는건 expolotation, 근데 우리가 원하는 agent를 만들기 위해선 exploration도 해야됨.

예를 들어 새로운 식당에 가는건 exploration, 갔던 식당에 가는건 explotation.
롤에서 했던 캐릭터만하는거는 explotation, 새로운 포지션을 하는건 exploration.
강화학습에서 많이 마딱뜨리는 문제이다.

이런 exploration explotation 문제를 다뤄야 하는 방법론들은 다음과 같다.

이제 개념설명을 위해 Multi-armed bandit을 문제환경을 알아야 한다.
mdp보다 간단한거.
슬롯머신마다 reward의 확률분포가 따로 있다. -> one step mdp
action과 reward만 있음.
각 스텝마다 하나의 머신을 당기면서 알아가야됨.
목표는 cummulate reward를 최대화 하고자함.

먼저 용어들을 정리해야되는데,
q(a) : 액션을 했을때 나오는 reward의 기댓값
optimal value는 내가 당길수있는 머신들의 reward중에 제일 좋은거.
regret은 내가 어떤 슬롯머신을 당겼을때의 reward와 optimal value간의 차이.
total regret은 n번 당겼을때의 regret을 다 더한거.
action에 종속된 함수.
목적은 regret을 줄여보자.
reward을 이용하지 않고 regret을 도입한 이유는 알고리즘이 가장 잘할수있는 한계가 어느정도인지, 우리의 이해에 도움을 주기 위해서다.

gap이란 개념도 나옴.
gap은 머신별로 정의되는데, 제일 좋은 머신에서 그 슬론머쉰의 reward를 뺸거.
그 머신이 다른것에 비해서 얼마나 딸리는건가.

total regret은 땡길때마다 늘어남.
greedy는 optimal을 하지않고 gap이 큰 머신을 선택 하기때문에
그리고 optimal을 찾아가더라도 epsilon 5%확률로 계속 바보짓을 함


optimistic initialization
모든 value들을 maximum으로 초기화한후에 greedy하게 (랜덤) action해서 나오는 reward로 평균해서 점점 낮춰감
랜덤하게 높은에만 하게됨
초기단계에 다 값이 높으니까 exploration을 하게됨.

epsilon을 어떤 스케쥴을 가지고 점점 줄여감
정보가 많이 쌓이면 epsilon을 줄여감.
저 식은 크게 신경쓰지 않아도 됨.
d는 1등 머신과 2등머신의 regression 차이
t가 분모에 있기때문에 step이 갈수록 epsilon이 줄어듬.
log함수형태의 점점 수렴해감

어떤 알고리즘도 lower bound가 존제함.
그리고 이 lower bound는 log함수이다.
lower bound, 제일 잘하는 머신의 performance가 있다.
그래서 문제의 난이도는 제일 잘하는 머신과 내 알고리즘의 performance가 클수록 어려운 문제가 됨.
문제를 아무리 잘짜도 log함수보다 아래로 갈수는 없으며 gap이 클수록 문제가 어려워짐.

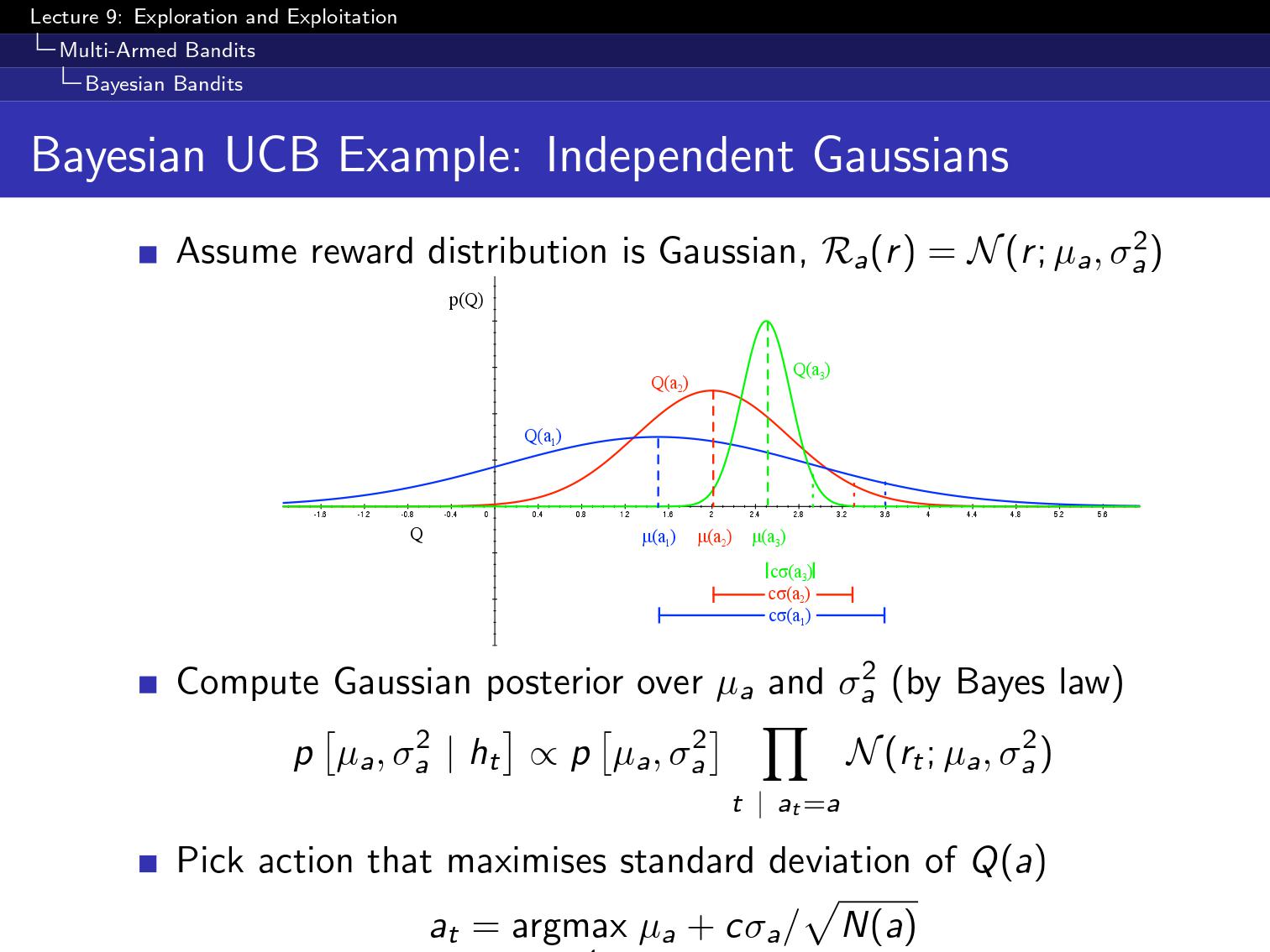
신뢰구간을 그린 그림인데 어떤 머신을 땅켜봐야겠나?
Optimism in the Face of Uncertainty : (a1)을 선택, uncertainty를 긍정적으로 보자는 철학이 있음.
더 잘 모르니까 더 best로 바뀔수 있음.

파란색이 선택됨으로 불확실성이 없어짐

신뢰구간이 있을때 각 action value upper confidence U()가 있다.
Q sample이 쌓이수록 높아지고,
N이 높아질수록 신뢰구간이 작아짐.
이걸 구체화 시키는데 크게 2가지 방법이 있다. frequentist, bayesian.

우선 Frequentist입장에서 분포와 관계없이 항상 쓸수있는건데,
이를 위해 필요한게 hoeffding 부등식,
X는 실제 모평균의 기댓값, u는 틀린정도인데, 그게 e^-2tu^2보다 이하다라는게 증명됨.
이를 이용해서 UCB를 구함.

이를 우리가 구하고자하는 확률로 맞춰서
Ut로 구함

그래서 이를 UCB1-> Q+U를 최대화하는 action을 선택하자

각 machine마다 나오는 확률이 다름.
epsilon greedy가 생각보다 괜찮은데 어떤경우 epsilon greedy가 제앙이 된다.
epsilon 을 잘 살정하면 괜찮다.

prior 분포를 가정함.
posterior 분포를 구하는것.


bayesian 방법론
각 머신의 확률분포에서 sampling함.
먼저 baye rule을 이용해서 posterior를 구하고나서 sample을 한다.
그 값을 가지고 제일 값이 높은놈을 선택함.

정보를 계량화 할수있을까?
uncertain한 상황에서 얻는 정보가 크다.

State Space에 정보를 더함.
지금까지는 one step MDP에서 a랑 r만 있었다.
근데 여기에다가 S history를 넣어줌.
그 state에서 알고있는 정보를 씀. 뒤에 붙어있는 vector가 다른거여서

bernoulli bandits을 예로 들면은
이기거나 질때
이때 information state는 베르누이 분포로 만들어주몀.
알파는 이겼을때 베타는 졌을때의 count

이제 information state을 이용한 mdp가 생긴거임.

baye rule을 이용한 분포
매번 transition 할때마다 그림을 update















'Backup > David Silver RL course' 카테고리의 다른 글
| [강화학습 4강] Model Free Prediction (0) | 2019.06.04 |
|---|---|
| [강화학습 2강] Markov Decision Process (0) | 2019.05.30 |
| [강화학습 1강] 강화학습 introduction (0) | 2019.05.27 |


