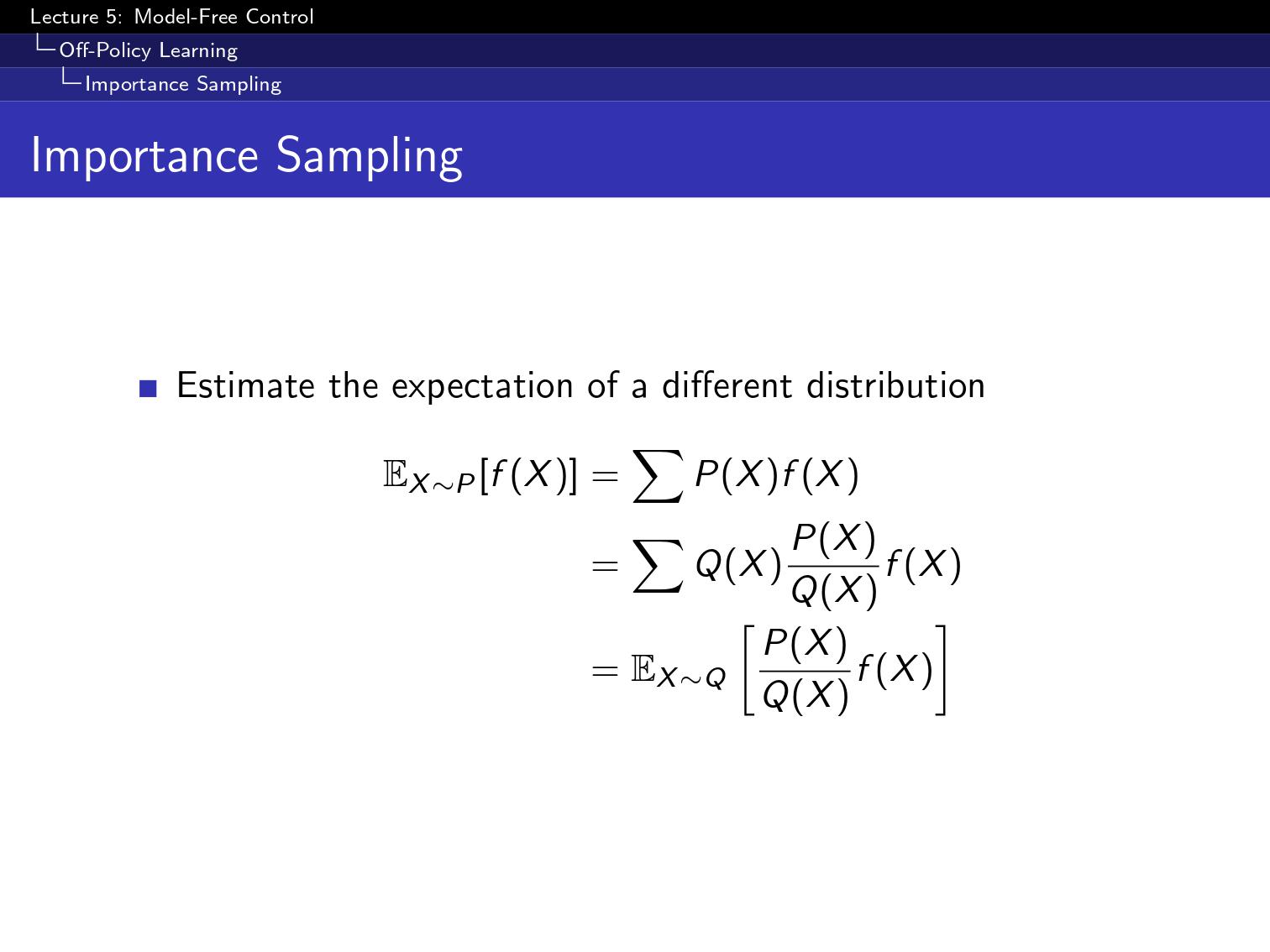
본격적으로 policy를 찾는거를 배워보자

* on policy는 학습하는 policy와 실제 environment에서 경험을 쌓는 policy가 같을때
-> MC를 이용한 learning과 TD를 이용한 learning

지난 시간엔 unknown MDP를 측정하는 법에 대해 배운

model free control이 어디서 쓰이는지에 대한 예

policy가 두개있다
하나는 내가 최적화 하고자하는 policy,
다른 하나는 behavior policy(environment에서 경험을 쌓는 policy)
이 두가지가 같으면 on-policy, 다르면 off-policy
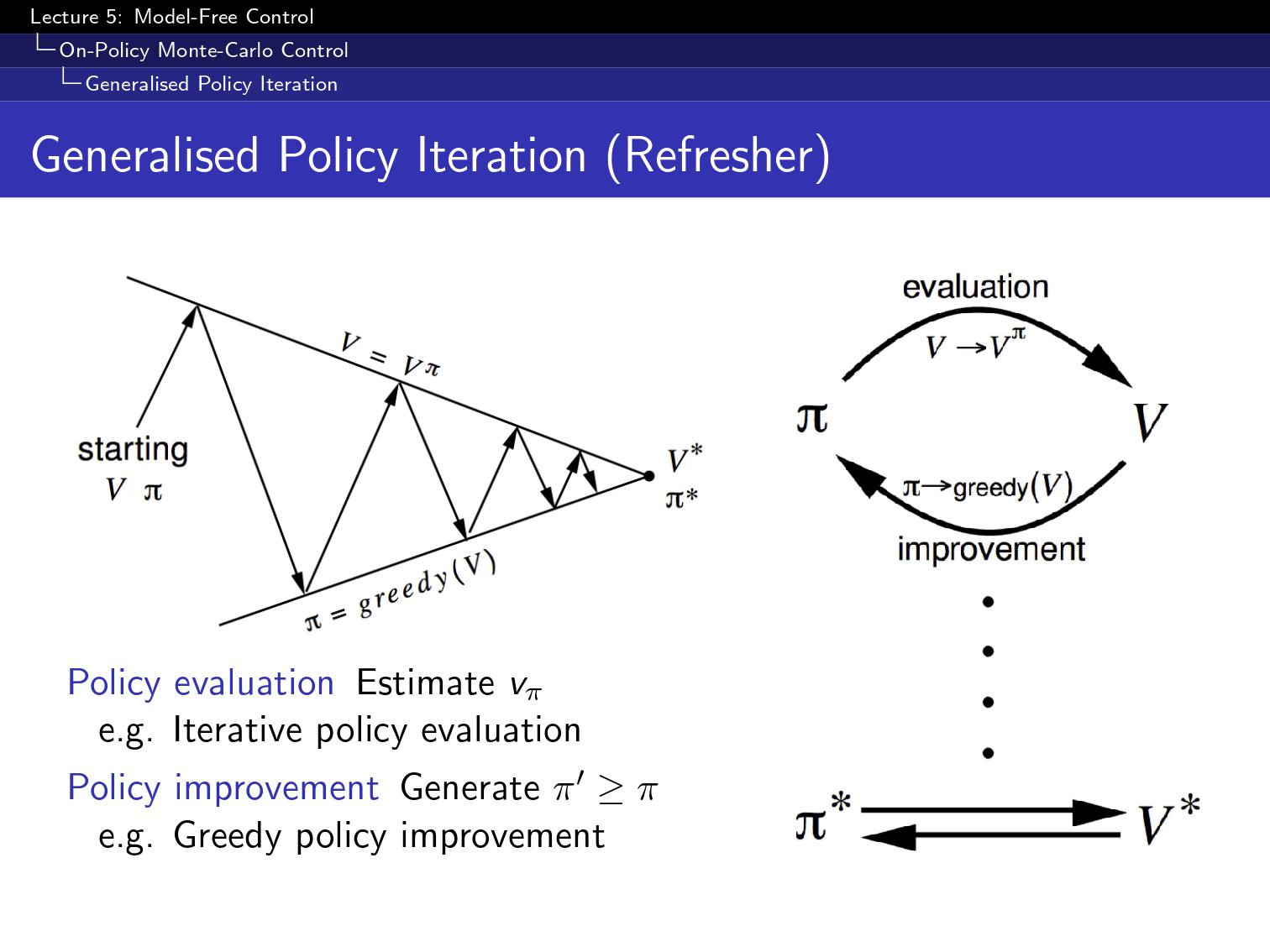
policy iteration은 결국에 (control)최적의 value function을 찾는 방법론
policy가 있을때 policy를 평가하고
그거에 대해서 greedy하게 policy를 학습하고
그리고나서 또 새로운 policy를 평가하고 하는것을 반복함.

이게 되면 좋겠지만
그런데 모델을 알아야 greedy policy를 update할수있다.

V같은경우 S에 대한 vector인데
Q가 (action-value function)은 state X action 만큼의 행렬이 있음

MC를 이용해서 Q를 평가하고
greedy로 improve
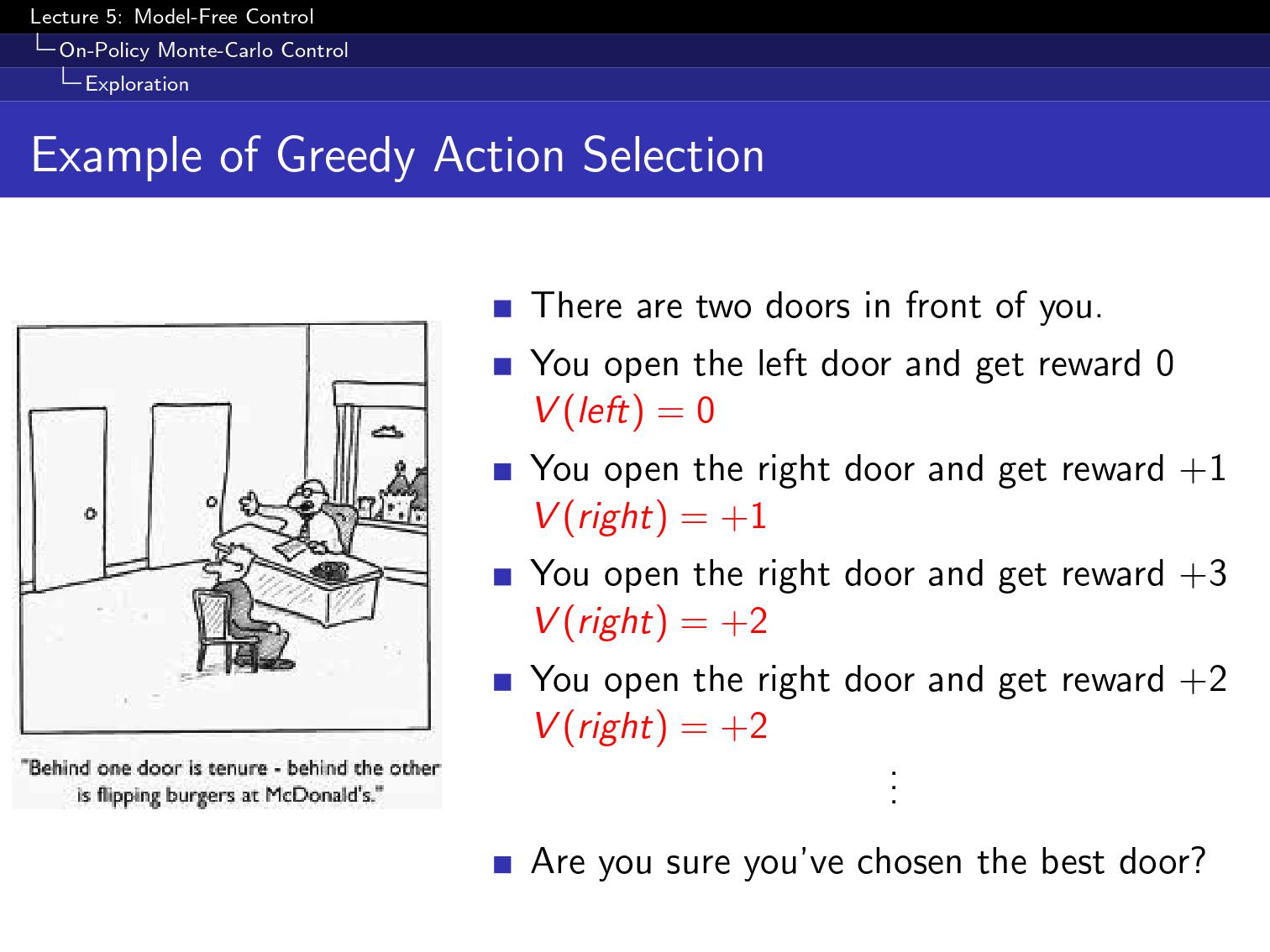
greedy하게만 선택해서는 최선을 찾는데 문제가 있다.

그래서 epsilon의 확률로 random하게 다른 선택을 해봄.

그래서 정리하자면
어떤 epsilon greedy를 해도 발전한다는걸 보여주는 수식이다.
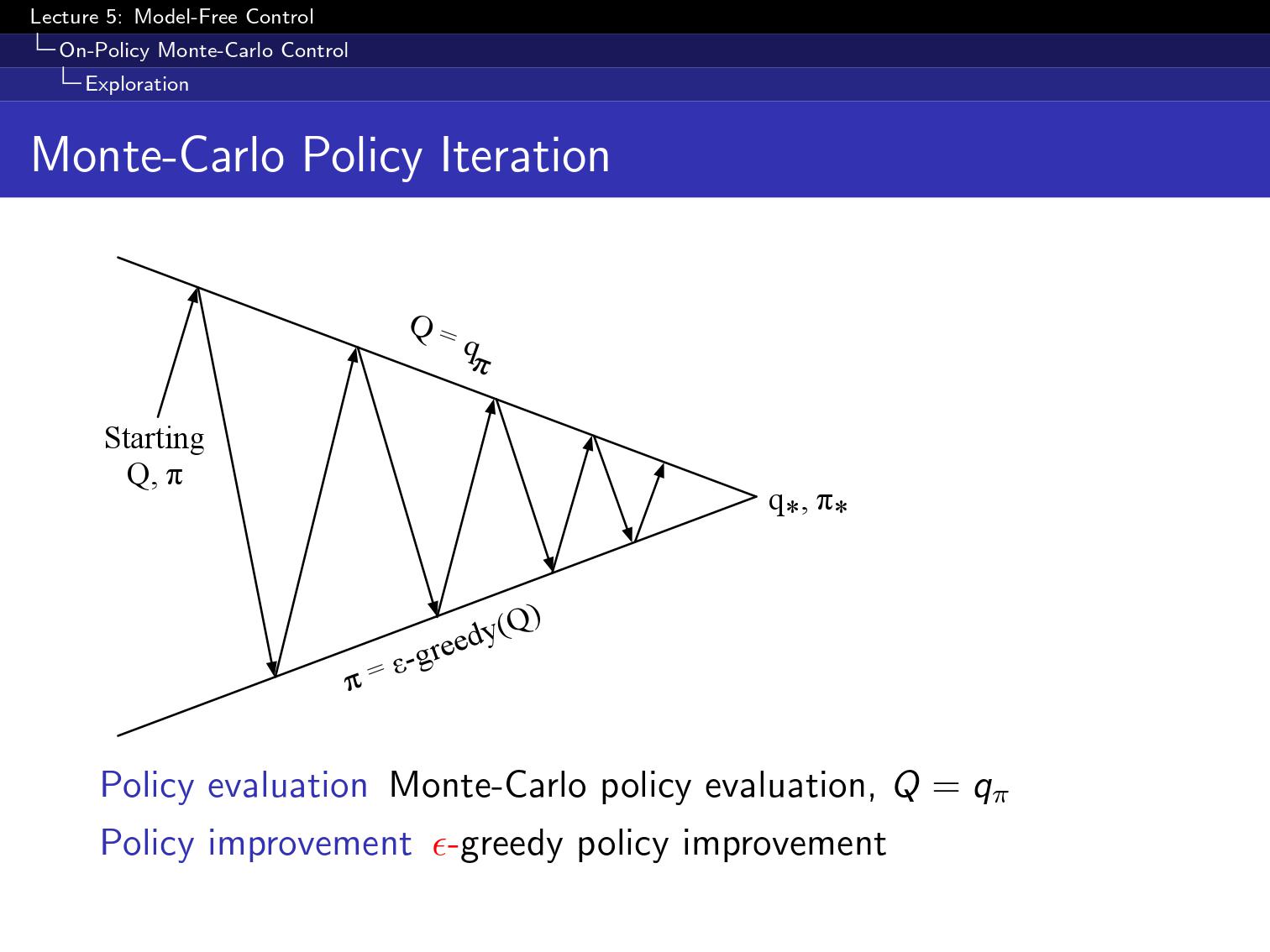

한 episode가 evaluation이 끝나고 바로 improve함

이걸 잘 하기위해 두가지 성질이 필요하다.
첫번째로는 GLIE,
모든 state들이 무한이 반복되어야됨.(exploration)

optimal policy여도 epsilon 5%만큼 바보같은 짓을 한다.
결국 greedy로 수렴을 위해 epsilon을 다음고 가타이 설정한다.



MC자리에 TD를 쓰면 어떨까
TD의 장점은 variance가 작고, online으로 학습할수있고 끝까지 안해도 된다.

그래서 이 알고리즘을 sarsa알고리즘이라 부름
이건 TD이기 때문에 episode가 끝나지 않아도 바로바로 update해줘도 됨.
저 뒷부분이 TD에러이다.


알고리즘의 순서도를 보자
1. lookup table Q(s,a)를 임의로 init
2. 할수있는 action중에 하나를 뽑음
그리고나서 다음관측치에서 어떤 action을 할지 뽑음
이거를 이용해서 현재의 Q를 update해줌

두가지조건을 만족해야되는데
하나는 GLIE조건을 만족하고
Robbins-Monro조건을 만족해야됨. = alpha를 다 더하면 무한이 되어야되고 Q를 수정하는 값이 점점 작아져야됨.

예시로 grid월드가 또 나왔다.
위쪽으로 바람이 부는데, 0인건 바람 이런 문제가 있다 가정.

첫 G까지 갈떄까지 2000 episode가 필요함
근데 우연히 1번 도착하면 그때부터 reward 정보가 전파되면서 나중에는 더 빨리 episode로 할수있음




backward-view td lambda